Web Scraping with Python
This is a tutorial on web scraping with Python. Learn to scrape websites with Python and BeautifulSoup.
- Setup web scraping with Python.
- Web scraping target and expected result.
- Setup logging in Python.
- Setup BeautifulSoup and export to CSV.
- Scrape one page.
- Scrape multiple pages.
To scrape or not to scrape
There are tools with a user interface that allow you to point to content on a page and they scrape everything for you.
There is also the question of scraping or not. Can you easily copy/paste the content and modify it with Excel? Or with a text editor like Sublime Text?
While some tools can scrape things for you, sometimes they are hard to customize, or you have to pay for additional features.
This tutorial assumes that you want the freedom to scrape anything you want and customize the tool however you think is best for your needs.
1. Setup web scraping with Python.
For this tutorial on web scraping I am using Python 3. There are a lot of tutorials online on how to install Python 3.
If you are new to Python. This tutorial might not be the best first step for you. Here are some good resources:
I am also using a virtual environment with miniconda
If you are not familiar with Unix commands. Here are some resources:
- Strongly recommend a book called “Unix for the Beginning Mage”. You can download it online.
- You can practice using this interactive shell on the browser:
https://www.learnshell.org/.
I am using Linux Fedora. The output of the commands you see in this tutorial might be different than yours.
Once you have Python3 and miniconda installed then you can setup a virtual environment like this:
$ conda create --name your-project
Activate:
$ conda activate your-project
Go back to base:
$ conda activate
2. Web scraping target and expected result.
If you made it to this point. It is downhill from here…that was a joke. It’s not :)
Unless you have some experience in Python. Then this should be easy.
What do you want to scrape? A page or multiple pages? What output do you want?
For this tutorial we are going to scrape speakers from a conference and the output is a CSV file with data about these speakers.

Let’s open the first speaker in another tab to see what content is there:
- Name of speaker
- Title
- Company
- Bio
Scraping metadata
What is else is there besides what we can read on the page?
Right click, Inspect.
It has meta name="keywords". Do we need these? Maybe.
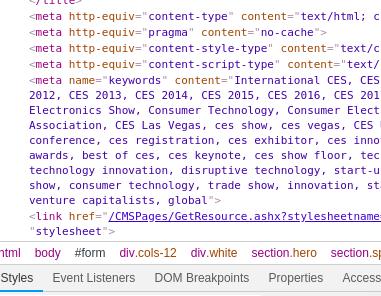
It has a meta name="description" with a shorter bio.
Scraping web content
The name of the speaker is under this tag:
<h1 class="global-hero__title">
I see a problem. The title and company are on the same sentence, separated by a comma and it is under this tag:
<h2 class="alt">Head of Studio, SoftBank Robotics</h2>
There is no separate tag between title name and company name.
On the other hand, the speakers list has title name and company name on different tags.
<h4 class="speaker-title">Head of Studio</h4>
<h4 class="speaker-company">SoftBank Robotics</h4>
Can I extract this content by just copy/pasting? It doesn’t seem so. The result is:
name
title
company
name
title
company
There is no way of knowing how to break this into a CSV file but we could take the risk of following the pattern of creating a speaker row for every 3 lines. Although I don’t see how to do this without writing some code.
We could also scrape the Speakers page but it doesn’t have the bios. It just has:
- name
- title
- company
To bio or not to bio
On the speakers page we have:
- name
- title
- company
- speaker conference url
- no bio
- Title and company are on different html tags.
On each speaker page we have:
- name
- title
- company
- bio
- Title and company are on the same html tag, separated by a comma.
Can we scrape the title and company from the same html tag? Then do some magic (regex) to separate the data?
What if the title already has a comma?
Such as:
- Name: Homer Simpson
- Title: Nuclear Engineer, Research
- Company: ACME, Inc
And the html tag has this: <h2 class="alt">Nuclear Engineer, Research, ACME, Inc</h2>.
This would be impossible to extract if speakers have different variations of where the comma is placed to separate title and company.
If we only scrape the speakers page then we will miss the bio.
3. Setup logging in Python.
Here is a Python logging tutorial to get all the details.
We want to capture a log file when running the script. That way we can see what worked and what didn’t. You could use print statements but it will be hard to read the terminal output after running the script a few times.
For this blog post we just have to add this code towards the top:
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
Then logger can be used as this:
Example 1:
for url in urls:
logger.info('Reading URL: %s', url)
Example 2:
page_title = soup.find('title').text
logger.info('page title captured: %s', page_title)
Then we have to close the log file at the end of the script:
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
4. Setup BeautifulSoup and export to CSV.
For both files we need to add this code:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup as bs
import csv
Why use urllib and not requests? It works and I always used it. But you are free to use any other library.
Followed by the logging setup
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
Followed by closing the logging file:
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
In between the logging setup we need to add our code.
Setup BeautifulSoup
Given a url:
url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
read_url = urllib.request.urlopen(url).read()
soup = bs(read_url, 'html.parser')
Read more about BeautifulSoup here:
Export data to a CSV file
The usual is to export the scraped data to a CSV file.
with open('leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['column1', 'column2', 'column3'])
Then after saving data into variables. Use writerow to save the data to the CSV file.
5. Scrape one page
So far we have this:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup as bs
import csv
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
with open('leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['column1', 'column2', 'column3'])
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
Let’s create two scripts and save this code to each:
one_page.pymany_pages.py
Scrape the page that has the list of speakers:
- Name
- Title
- Company
- Speaker conference url
- No bio
Modify the name of the log file. From output.log to one_page_output.log.
Add the url and create a BeautifulSoup object.
url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
read_url = urllib.request.urlopen(url).read()
soup = bs(read_url, 'html.parser')
Then create the CSV file:
with open('one_page_leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['name', 'title', 'company', 'url'])
Instead of running the script multiple times to try to scrape the data. I like to work on the Python shell to see the results and then add the code to the script.
Test scraping using the shell:
(env)$ python
>>>
Then setup the script with BeautifulSoup:
>>> from bs4 import BeautifulSoup as bs
>>> import urllib.request, urllib.parse, urllib.error
>>> url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
>>> urlopen = urllib.request.urlopen(url).read()
>>> soup = bs(urlopen, 'html.parser')
Now we need to Inspect the HTML on the page and use soup methods to extract the data.

To view soup methods you can try:
>>> dir(soup)
It will show a list of all methods.
Get some help about a method using help:
>>> help(soup.find)
It shows the following syntax:
find(name=None, attrs={}, recursive=True, text=None, **kwargs)
Each speaker has an HTML that looks like this:
<aside class="speaker-photo directory small">
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<picture class="head-shot" style="background-image: url('https://hubb.blob.core.windows.net/e955a157-fba9-4f75-9465-67396ae15f0e-profile/546100')"></picture>
</a>
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<h3 class="speaker-name">Omar Abdelwahed </h3>
</a>
<h4 class="speaker-title">Head of Studio</h4>
<h4 class="speaker-company">SoftBank Robotics</h4>
</aside>
The parent tag is:
<aside class="speaker-photo directory small">
The child tags have this content:
<h3 class="speaker-name"><h4 class="speaker-title"><h4 class="speaker-company"><a href="/conference/speaker-directory/...
Which correspond to name, title, company and url.
Scrape one name
>>> soup.find('h3', attrs={'class': 'speaker-name'})
The output is:
<h3 class="speaker-name">Omar Abdelwahed </h3>
This is correct but we only want the text inside the tag.
>>> soup.find('h3', attrs={'class': 'speaker-name'}).text
'Omar Abdelwahed '
But this only finds one name.
Scrape all the names
This doesn’t work:
>>> soup.find_all('h3', attrs={'class': 'speaker-name'}).text
It has this error:
Traceback (most recent call last):
AttributeError: ResultSet object has no attribute 'text'.
You're probably treating a list of items like a single item.
Did you call find_all() when you meant to call find()?
Then try this:
>>> soup.find_all('h3', attrs={'class': 'speaker-name'})
The output is a list of soup objects with the <h3 class="speaker-name"> tag and text.
Scraping and matching rows
I thought of this. We can scrape the list of names. But what about the other data that corresponds to each speaker.
The names could be:
names = [name1, name2, name3, ...]
Then titles:
titles = [title1, title2, title3,...]
But how do we join these two lists? What if the data doesn’t match?
We need to find the correct data structure to put all the scraped data.
Scraping the parent tag
The parent tag that has the data for each speaker is:
<aside class="speaker-photo directory small">
We can use this code to find the first speaker:
>>> soup.find('aside', attrs={'class': 'speaker-photo directory small'})
<aside class="speaker-photo directory small">
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<picture class="head-shot" style="background-image: url('https://hubb.blob.core.windows.net/e955a157-fba9-4f75-9465-67396ae15f0e-profile/546100')"></picture>
</a>
<caption class="speaker-info">
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<h3 class="speaker-name">Omar Abdelwahed </h3>
</a>
<h4 class="speaker-title">Head of Studio</h4>
<h4 class="speaker-company">SoftBank Robotics</h4>
</caption>
</aside>
Use this code to put the HTML content for all speakers into a list:
>>> soup.find_all('aside', attrs={'class': 'speaker-photo directory small'})
Assign to a variable:
>>> speakers = soup.find_all('aside', attrs={'class': 'speaker-photo directory small'})
Use this: speakers[0] to see the content of the first speaker.
<aside class="speaker-photo directory small">
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<picture class="head-shot" style="background-image: url('https://hubb.blob.core.windows.net/e955a157-fba9-4f75-9465-67396ae15f0e-profile/546100')"></picture>
</a>
<caption class="speaker-info">
<a href="/conference/speaker-directory/Omar-Abdelwahed">
<h3 class="speaker-name">Omar Abdelwahed </h3>
</a>
<h4 class="speaker-title">Head of Studio</h4>
<h4 class="speaker-company">SoftBank Robotics</h4>
</caption>
</aside>
Now we can get separate the data for each speaker…
Actually I am not sure what methods I can use. Let’s use help:
>>> help(speakers[0])
Help on Tag in module bs4.element object:
class Tag(PageElement)
| Represents a found HTML tag with its attributes and contents.
|
| Method resolution order:
| Tag
| PageElement
| builtins.object
|
| Methods defined here:
This documentation is long. Here is an extract:
|
| find(self, name=None, attrs={}, recursive=True, text=None, **kwargs)
| Return only the first child of this Tag matching the given
| criteria.
|
| findAll = find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
|
| findChild = find(self, name=None, attrs={}, recursive=True, text=None, **kwargs)
| findChildren = find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
|
| find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs)
| Extracts a list of Tag objects that match the given
| criteria. You can specify the name of the Tag and any
| attributes you want the Tag to have.
|
| The value of a key-value pair in the 'attrs' map can be a
| string, a list of strings, a regular expression object, or a
| callable that takes a string and returns whether or not the
| string matches for some custom definition of 'matches'. The
| same is true of the tag name.
|
| get(self, key, default=None)
| Returns the value of the 'key' attribute for the tag, or
| the value given for 'default' if it doesn't have that
| attribute.
|
| getText = get_text(self, separator='', strip=False, types=(<class 'bs4.element.NavigableString'>, <class 'bs4.element.CData'>))
|
| get_attribute_list(self, key, default=None)
| The same as get(), but always returns a list.
| get_text(self, separator='', strip=False, types=(<class 'bs4.element.NavigableString'>, <class 'bs4.element.CData'>))
| Get all child strings, concatenated using the given separator.
|
Scrape the URL
Here is the code to capture the URL bio from speakers[0]:
>>> speakers[0].find('a').get('href')
'/conference/speaker-directory/Omar-Abdelwahed'
Scrape the name
This is the HTML that contains the name:
<h3 class="speaker-name">Omar Abdelwahed </h3>
Use this code to scrape the name:
>>> speakers[0].find('h3', attrs={'class': 'speaker-name'}).text
'Omar Abdelwahed '
I see it has whitespace at the end of the string. But not sure if this is just this one or all of them. Not a big deal for now.
Scrape the title
This HTML has the title:
<h4 class="speaker-title">Head of Studio</h4>
Use this code:
>>> speakers[0].find('h4', attrs={'class': 'speaker-title'}).text
'Head of Studio'
Scrape the company
This HTML has the company:
<h4 class="speaker-company">SoftBank Robotics</h4>
Use the code:
>>> speakers[0].find('h4', attrs={'class': 'speaker-company'}).text
'SoftBank Robotics'
Add this code to the script one_page.py
We don’t need to use speakers[0] anymore. We are going to find all speakers into a list. Then use a loop to scrape the data from each speaker. Then write the row to CSV.
We are going to use exceptions in case a data value from a speaker is not found.
And we will add logging for each step.
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup as bs
import csv
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('one_page_output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
read_url = urllib.request.urlopen(url).read()
soup = bs(read_url, 'html.parser')
with open('one_page_leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['name', 'title', 'company', 'url'])
speakers = soup.find_all('aside', attrs={'class': 'speaker-photo directory small'})
for speaker in speakers:
logger.info('Scraping a speaker...')
print('Scraping a speaker...')
try:
url = speaker.find('a').get('href')
except:
logger.info('No URL found')
url = 'Not found'
try:
name = speaker.find('h3', attrs={'class': 'speaker-name'}).text
except:
logger.info('Name not found')
name = 'Not found'
try:
title = speaker.find('h4', attrs={'class': 'speaker-title'}).text
except:
logger.info('Title not found')
title = 'Not found'
try:
company = speaker.find('h4', attrs={'class': 'speaker-company'}).text
except:
logger.info('Company not found')
company = 'Not found'
logger.info('Saving %s to CSV', name)
csvwriter.writerow([name, title, company, url])
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
Running the script one_page.py
Run the script with:
$ python one_page.py
It will take a few seconds to capture the page and then it will print to the terminal:
Scraping a speaker...
Scraping a speaker...
Scraping a speaker...
Scraping a speaker...
Scraping a speaker...
...
Review the log file
We saved the log file with this name: one_page_output.log
It looks like it scraped all the data.
Review the CSV file
We named the CSV file: one_page_leads.csv.
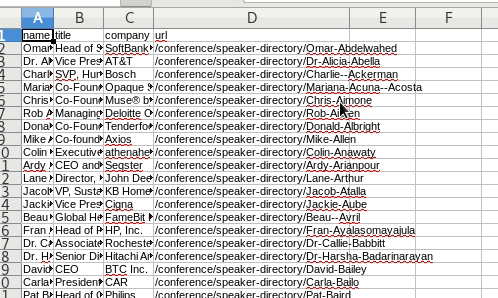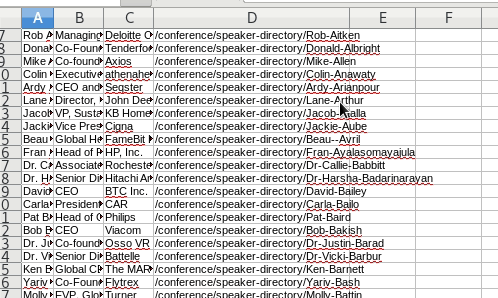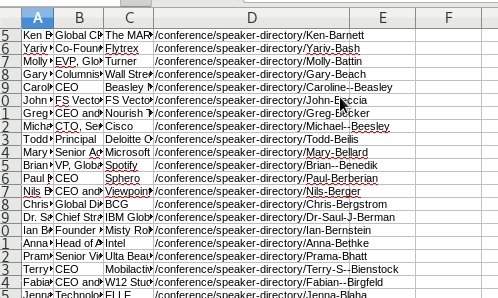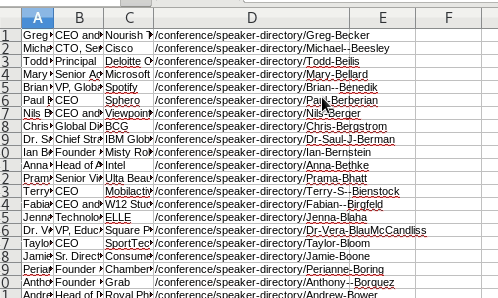
It looks good. But the dilemma continues. We don’t have the bios.
6. Scrape multiple pages.
We can add more to the script if we really want the bio for each speaker.
Let’s just copy the script over to a new file: many_pages.py.
But first let’s test how to get a bio using the Python shell.
The first URL from the CSV file is this:
/conference/speaker-directory/Omar-Abdelwahed
Go to the shell:
>>> from bs4 import BeautifulSoup as bs
>>> import urllib.request, urllib.parse, urllib.error
>>> url = 'https://www.ces.tech/conference/speaker-directory/Omar-Abdelwahed'
>>> urlopen = urllib.request.urlopen(url).read()
>>> soup = bs(urlopen, 'html.parser')
Previously we saw that there were 2 bios.
Short bio
This metadata has a short bio:
<meta name="description" content="Omar Abdelwahed is Head of Studio at SoftBank Robotics America where he is responsible for leading the development of robotics applications in America, and the overall user experience, globally">
Scrape it with:
>>> soup.find('meta', attrs={'name': 'description'}).get('content')
'Omar Abdelwahed is Head of Studio at SoftBank Robotics America where he is responsible for leading the development of robotics applications in America, and the overall user experience, globally'
Long bio
This tag has a long bio:
<article class="speaker-bio">
<p>Omar Abdelwahed is Head of Studio at SoftBank Robotics America where he is responsible for leading the development of robotics applications in America, and the overall user experience, globally. Previously, Omar was VP of Engineering at Mighty Play, a game developer in San Francisco. Omar has over 20 years of experience as an engineer with a deep background in entertainment and technology. Omar’s career has spanned large video game publishers, retailers, startups, and his own independent work. Omar is the founder of Agent Disco, an independent mobile games developer. He is a frequent conference speaker on technology topics, including AI, robotics, data privacy, and product development.</p>
<div>
</div>
</article>
Scrape it with:
>>> soup.find('article', attrs={'class': 'speaker-bio'}).find('p').text
'Omar Abdelwahed is Head of Studio at SoftBank Robotics America where he is responsible for leading the development of robotics applications in America, and the overall user experience, globally. Previously, Omar was VP of Engineering at Mighty Play, a game developer in San Francisco. Omar has over 20 years of experience as an engineer with a deep background in entertainment and technology. Omar’s career has spanned large video game publishers, retailers, startups, and his own independent work. Omar is the founder of Agent Disco, an independent mobile games developer. He is a frequent conference speaker on technology topics, including AI, robotics, data privacy, and product development.'
Looks like the short bio is the first sentence up to the first period. For others it might or might not be the same.
Maybe we should scrape both just in case.
I opened a few profiles and noticed some have additional data.
Linkedin URL
Found that this profile:
https://www.ces.tech/conference/speaker-directory/Charlie--Ackerman.aspx
Has a Linkedin URL:
<a href="https://www.linkedin.com/in/charlie-ackerman-56499013/" target="_blank" class="fab fa-linkedin"></a>
Scrape it with:
>>> soup.find('a', attrs={'class': 'fab fa-linkedin'}).get('href')
'https://www.linkedin.com/in/charlie-ackerman-56499013/'
Modifying the script many_pages.py
Same setup as before but change log file name and csv file name:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup as bs
import csv
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('many_pages_output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
read_url = urllib.request.urlopen(url).read()
soup = bs(read_url, 'html.parser')
with open('many_pages_leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['name', 'title', 'company', 'url'])
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
We need to make some additional changes.
Once we capture each URL we need to scrape the data:
- short bio
- long bio
- Linkedin URL
Change the column names of the CSV file:
with open('many_pages_leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['name', 'title', 'company', 'url', 'short_bio', 'long_bio', 'linkedin'])
A scraped URL has this form:
/conference/speaker-directory/Omar-Abdelwahed
To scrape this page we need the complete URL. Maybe add this variable:
root_url = 'https://www.ces.tech'
The final script is this
Ideally this could be broken into modules but for now this is the final script:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup as bs
import csv
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('many_pages_output.log')
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter(('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
fh.setFormatter(formatter)
logger.addHandler(fh)
root_url = 'https://www.ces.tech'
url = 'https://www.ces.tech/Conference/Speaker-Directory.aspx'
urlopen = urllib.request.urlopen(url).read()
soup = bs(urlopen, 'html.parser')
with open('many_pages_leads.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(['name', 'title', 'company', 'url', 'short_bio', 'long_bio', 'linkedin'])
speakers = soup.find_all('aside', attrs={'class': 'speaker-photo directory small'})
for speaker in speakers:
logger.info('Scraping a speaker...')
print('Scraping a speaker...')
try:
name = speaker.find('h3', attrs={'class': 'speaker-name'}).text
except:
logger.info('Name not found')
name = 'Not found'
try:
title = speaker.find('h4', attrs={'class': 'speaker-title'}).text
except:
logger.info('Title not found')
title = 'Not found'
try:
company = speaker.find('h4', attrs={'class': 'speaker-company'}).text
except:
logger.info('Company not found')
company = 'Not found'
try:
url = speaker.find('a').get('href')
url_speaker = urllib.request.urlopen(root_url + url).read()
soup_speaker = bs(url_speaker, 'html.parser')
# Get short bio
try:
short_bio = soup_speaker.find('meta', attrs={'name': 'description'}).get('content')
except:
logger.info('Short bio not found')
short_bio = 'Not found'
# Get long bio
try:
long_bio = soup_speaker.find('article', attrs={'class': 'speaker-bio'}).find('p').text
except:
logger.info('Long bio not found')
long_bio = 'Not found'
# Get Linkedin
try:
linkedin = soup_speaker.find('a', attrs={'class': 'fab fa-linkedin'}).get('href')
except:
logger.info('Linkedin URL not found')
linkedin = 'Not found'
except:
logger.info('URL not found')
url = 'Not found'
logger.info('Saving %s to CSV', name)
csvwriter.writerow([name, title, company, url, short_bio, long_bio, linkedin])
for handler in logger.handlers:
handler.close()
logger.removeHandler(handler)
Reviewing results
You can open the log file in Sublime to see progress. Or just monitor the file size and you will see the log file increasing size.
Open the CSV file to see the output so far:
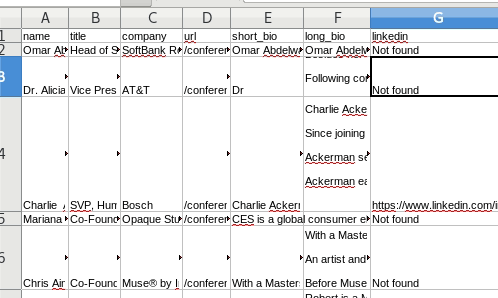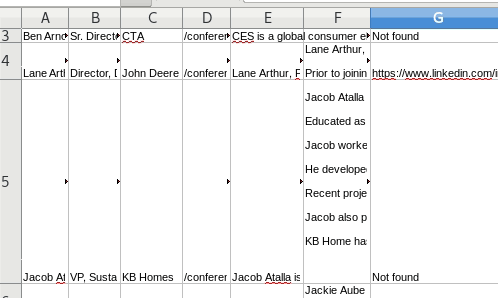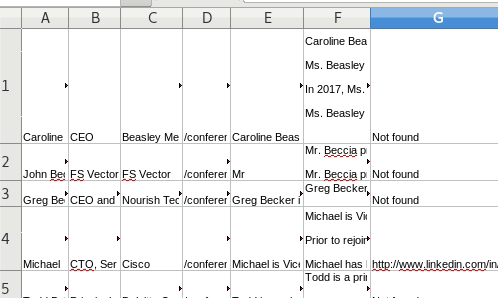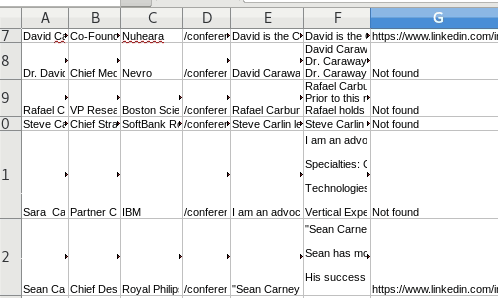
To module or not to module
This looks like a one-time script. A sort of scrape-on-demand. Scrape a specific page and move on. Another scrape project would have a different HTML structure depending on what you want to scrape.
You could use the same setup for logging and CSV but there is room for growth if you break this into modules:
- Ask for user input instead of hardcoding the URLs.
- Use a
mainfunction for the setup. - Use modules for scraping.
- Use a random function to ease on the scraping.of hardcoding the URLs.